
One of the recent topics I dove into for my project Todool was Spell Checking.
Obviously spell checking itself tends to be very complex due to each language having their own complex rules, but you can accomplish basic English spell checking as described here.
In short here's how it works:
- load English ebook (ASCII)
- read through all words (lowercase all characters)
- add each word to a hashmap
Spell Checking is finding if a key: string exists in the map. You can also apply modification as described in the blog to check for offspring of the key you're searching for.
The ebook I'm using has ~30_000 unique words that will be added to the map - this can quickly use up a lot of memory in your program. Which is what we will dive into now
String Storage
We want to store all these unique words in a data structure, use as little memory as possible and also allow searching the data structure quickly.
Wikipedia has a good section on data structures that exist for strings.
The Trie stands out to me as the simplest way to describe a ASCII word tree.
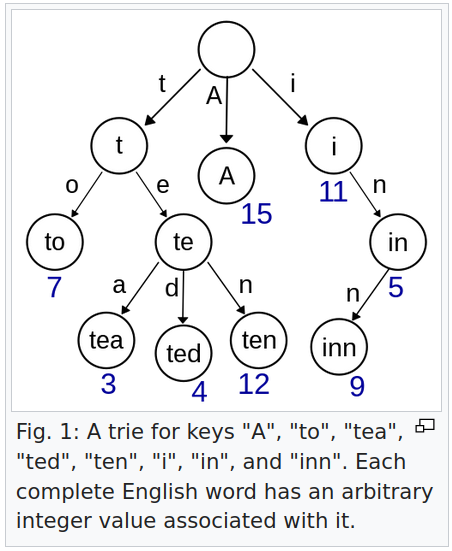
The other data structures tend to quickly get complicated to implement - but offer other benefits like supporting UTF8 strings or offering less memory usage.
Trie Implementation (in odin)
Tries are very basic to implement and test out.
// [a-z] only ALPHABET_SIZE :: 26 // treats nil pointer as non existant node // array['a'] = nil -> 'a' doesn't exist // array['b] = {} -> 'b' exists Trie :: struct { array: [ALPHABET_SIZE]^Trie, }
I'll leave implementing the insert & search operations for the trie up to you as an exercise.
You can see the data structure is really simple but it uses up 26 * size_of(^Trie) == 208B per Trie created.
More compact?
Here is another approach to reduce this by half, storing only 104B per Trie Node as indexes use 4B less.
// treats 0 as nil // // u32 is an index into some array where all the node data is stored // instead of allocating nodes through: new(Trie) CTrie :: struct { array: [ALPHABET_SIZE]u32, } // the root of the trie can be the first element of your data // root := ctrie_data[0] ctrie_data: [dynamic]CTrie
Anything better?
You can use a Linked List instead of an array, but this reduces the speed of the searching operation -> since now you can't directly access the searched characters anymore.
In the Spell Checker we want the searching operation to be the fast though - the insertion can be done at iniationlization once.
Is there a way to reduce this further? Give it a try yourself.
Setting Yourself Restrictions
Due to the nature of Trees it's hard to reduce memory usage as you have to support inserting elements at any node.
One way of achieving less memory usage is by setting yourself restrictions or finding out how you will use the trie in the end.
In my case I would like to
- preprocess the Trie Tree of my Spell Checker into a binary blob that I can bake into my application
- not ship the ebook itself
- never insert into the Trie Tree after it was initialized
- no post processing after I load the binary blob
Alphabet Bitfield
One way to replace the [ALPHABET_SIZE] array is by using a bitfield. We have 26 characters from [a-z] that could all exist - meaning 26 bits will be necessary.
We can fill such an alphabet bitfield in a u32 - here is a quick showcase of this.
main :: proc() { ALPHABET_SIZE :: 26 alphabet_bits := u32(0b1101) for i in 0..<u32(ALPHABET_SIZE) { mask := u32(1 << i) if alphabet_bits & mask == mask { fmt.eprintf("found bit %v = %v\n", i, rune(i + 'a')) } } }
results in
found bit 0 = a found bit 2 = c found bit 3 = d
Using the bitfield uses less memory and is still powerful enough.
We can count all the 1 in the bits to determine how many characters are supported: intrinsic.
We can check if the bits == 0 to skip processing early as the bitfield is empty and doesnt contain any valid bits.
Bitfield Trie "Compression"
The bitfield helps not using the array as we go from atleast 26B -> 4Bbut now we have the issue of not knowing which bit belongs to which Pointer or Index Handle.
As we want to reduce memory usage we will have to go the "relative" path, in which we know that after a bitfield -> there will be N trie nodes coming up.
I will present a way to go from a Trie or CTrie structure I've shown before to this "compressed" form of the trie that uses alphabet bitfields.
// globals // contains bitfield u32 and [N]u32 indices into the comp array // [u32][2x u32 u32] -> [u32][3x u32 u32 u32] -> [u32][0x] -> [u32][1x u32] // index 0 is the root bitfield comp: []byte // index we advanced the compressed data comp_index: int
We'll need one procedure to add a bitfield in the byte array and return the pointer so that we can modify it
// push u32 alphabet bits data comp_push_bits :: proc() -> (res: ^u32) { old := comp_index res = cast(^u32) &comp[old] comp_index += size_of(u32) return }
Next we need a way to create the necessary indice array based on the ones we got from counting.
// push trie children nodes as indexes comp_push_data :: proc(count: int) -> (res: []u32) { old := comp_index res = mem.slice_ptr(cast(^u32) &comp[old], count) comp_index += size_of(u32) * count return }
Combined together we can now recursively step through the CTrie and push the correct data to the byte array
// push a ctrie bitfield and its dynamic data comp_push_ctrie :: proc(t: ^CTrie, previous_data: ^u32) { if previous_data != nil { previous_data^ = u32(comp_index) } alphabet_bits := comp_push_bits() for i in 0..<ALPHABET_SIZE { if t.array[i] != 0 { alphabet_bits^ = bits.bitfield_insert_u32(alphabet_bits^, 1, uint(i), 1) } } if alphabet_bits^ != 0 { ones := bits.count_ones(alphabet_bits^) data := comp_push_data(int(ones)) index: int for i in 0..<ALPHABET_SIZE { if t.array[i] != 0 { comp_push_ctrie(ctrie_get(t.array[i]), &data[index]) index += 1 } } } }
That's it! Essentially we're removing the dynamic nature of the tree and keeping memory usage at a minimum.
Search Operation
The search operation can now use this "compressed" form of the trie directly by using using bitfields and stepping through the memory correctly
Here is a simple example for my Spell Checker
comp_search :: proc(key: string) -> bool { alphabet := mem.slice_data_cast([]u32, comp) next := u32(0) for i in 0..<len(key) { b := ascii_check_lower(key[i]) if ascii_is_letter(b) { letter := b - 'a' if res, ok := comp_bits_index_to_counted_one(alphabet[next], u32(letter)); ok { next = alphabet[next + res + 1] / size_of(u32) } else { return false } } else { return false } } return true }
Source Code
You can find my implementation of the CTrie and the Bitfield Trie here
Results
The ~30_000 unique words take up:
SIZE in 8183968B 7992KB 7MB for CTrie -> default Trie would be 2x this SIZE in 629532B 614KB 0MB for compressed
The compressed byte array can be exported to a file, loaded back on startup or baked into the application and be immediatly usable :)
End
Didn't think this blog would be this long but hopefully this demonstrates that even a basic data structure can be used for a basic Spell Checker.
Any time I searched for more memory efficient Trie's the answers would be: Use x because it's better or Use x library without going indepth.
Update 1
Another way to reduce the "compressed" result is to cut off tries with only 1 valid bit in long chains.
Here is an example where you can see the alphabet bit count.
2bit -> 2b -> 1b -> 2b -> 1b -|||> 1b -> 1b ->1b where ||| would be the region we shortcut and instead store the bytes linearly.
Ctrie Data
A minor thing I added for pre generating the CTrie was including a count so you don't manually have to check for the filled out array indices.
CTrie :: struct #packed { array: [ALPHABET_SIZE]u32, count: u8, // count of used array fields }
Ctrie Push
Down below you can see checking for single branches only is a step we do before proceeding with the default recursive nature of traversing the Ctrie tree.
We check wether the curren trie has 1 alphabet bit only and check for any chains of this happening till the end of its trie tree.
When they are all 1 or 0 length only we can concatenate the characters together and insert that string into the byte array.
The string length is then stored in the first [0-26] bits and the rest [26-32] bits indicates the bitfield is a shortcut, which we can check for early.
// push a ctrie bitfield and its dynamic data comp_push_ctrie :: proc(t: ^CTrie, previous_data: ^u32) { if previous_data != nil { previous_data^ = u32(comp_index) } alphabet_bits := comp_push_bits() // on valid sub nodes -> insert data if t.count != 0 { field: u32 // check for single branches only if t.count == 1 { single_index = 0 single_only := ctrie_check_single_only(t) // fmt.eprintln("single_only?", single_only) if single_only { // insert shortcut signal field = SHORTCUT_VALUE // insert string length field = bits.bitfield_insert_u32(field, u32(single_index), 0, 26) // insert characters comp_push_shortcut(t) } } // if nothing was set if field == 0 { data := comp_push_data(int(t.count)) index: int for i in 0..<uint(ALPHABET_SIZE) { if t.array[i] != 0 { field = bits.bitfield_insert_u32(field, 1, i, 1) comp_push_ctrie(ctrie_get(t.array[i]), &data[index]) index += 1 } } } // only set once alphabet_bits^ = field } }
Clever For Loop
Jeroen showed me a neat way to traverse the alphabet bitfield easier and shortcut once the bitfield is empty (early).
Original:
for i in 0..<u32(ALPHABET_SIZE) { mask := u32(1 << i) if alphabet_bits & mask == mask { fmt.eprintf("found bit %v = %v\n", i, rune(i + 'a')) } }
Idea - shift the copied bits and test the first bit:
for i in 0..<u32(ALPHABET_SIZE) { if alphabet_bits & 1 == 1 { fmt.eprintf("found bit %v = %v\n", i, rune(i + 'a')) } alphabet_bits >>= 1 }
Valid Usage - with index - ends early due to bits > 0:
bits := alphabet_bits for i := 0; bits > 0; i += 1 { if bits & 1 == 1 { fmt.eprintf("found bit %v = %v\n", i, rune(i + 'a')) } bits >>= 1 }
We check for the SHORTCUT_VALUE early but you could also clear the upper bits like this:
ALPHABET_MASK :: u32(1 << 26) - 1 bits := alphabet_bits & ALPHABET_MASK for i := 0; bits > 0; i += 1 { if bits & 1 == 1 { fmt.eprintf("found bit %v = %v\n", i, rune(i + 'a')) } bits >>= 1 }
Update 1 - Source Code
SIZE in 8262660B 8069KB 7MB for CTrie SIZE in 346683B 338KB 0MB for compressed
-> https://pastebin.com/rbj1weKq
-> ebook print output ebook.txt